24 Jan Pandas – Cleaning the Data
To clean the data in Python, we have some built-in functions. In this lesson, we will understand them one by one with examples. Cleaning the data in Pandas means working on the incorrect data to fix it. This incorrect data can empty data, null, duplicate data, etc.
Before moving further, we’ve prepared a video tutorial to clean the data with Pandas:
Read: Handle Duplicate Data in Pandas
Let’s say we have the following CSV file demo.csv. The data consists of some null values:
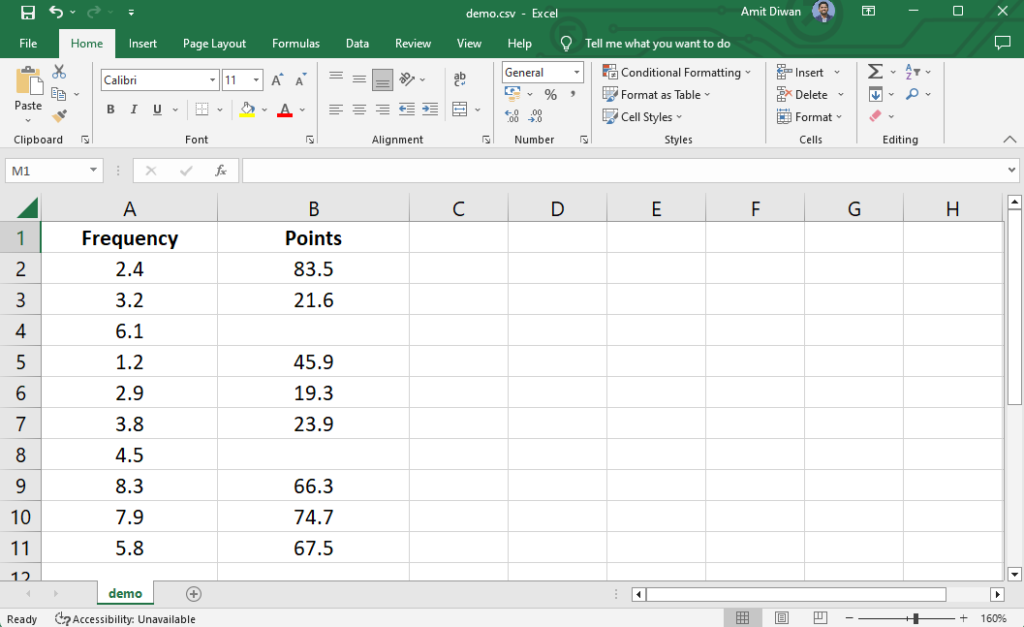
Let us now work around the functions to clean the data:
- isnull(): Find the NULL values and replace them with True.
- notnull(): Find the NOT NULL values and replace them with True.
- df.dropna(): Drop rows with NULL values.
- df.fillna(x): Replace NULL values with a specific value
Pandas isnull() method
The isnull() method in Pandas is used to find the NULL values and replace them with True. For non-NULL values, False is returned. Let us see an example:
import pandas as pd
# Input CSV file
df = pd.read_csv(r"C:\Users\hp\Desktop\demo.csv")
# Display the CSV file records
print("Our DataFrame\n",df)
# Find and Replace Null with True
resdf = df.isnull()
# Return the new DataFrame
print("\nNew DataFrame \n",resdf.to_string())
Output
Our DataFrame
Frequency Points
0 2.4 83.5
1 3.2 21.6
2 6.1 NaN
3 1.2 45.9
4 2.9 19.3
5 3.8 23.9
6 4.5 NaN
7 8.3 66.3
8 7.9 74.7
9 5.8 67.5
New DataFrame
Frequency Points
0 False False
1 False False
2 False True
3 False False
4 False False
5 False False
6 False True
7 False False
8 False False
9 False False
Pandas notnull() method
The notnull() method in Pandas is used to find the NOT NULL values and replace them with True. For NULL values, False is returned. Let us see an example:
import pandas as pd
# Input CSV file
df = pd.read_csv(r"C:\Users\hp\Desktop\demo.csv")
# Display the CSV file records
print("Our DataFrame\n",df)
# Find and Replace NOT NULL values with True
resdf = df.notnull()
# Return the new DataFrame
print("\nNew DataFrame\n",resdf.to_string())
Output
Our DataFrame
Frequency Points
0 2.4 83.5
1 3.2 21.6
2 6.1 NaN
3 1.2 45.9
4 2.9 19.3
5 3.8 23.9
6 4.5 NaN
7 8.3 66.3
8 7.9 74.7
9 5.8 67.5
New DataFrame
Frequency Points
0 True True
1 True True
2 True False
3 True True
4 True True
5 True True
6 True False
7 True True
8 True True
9 True True
Pandas dropna() method
The dropna() method in Pandas is used to drop and remove rows with null values. Let us see an example:
import pandas as pd
# Input CSV file
df = pd.read_csv(r"C:\Users\hp\Desktop\demo.csv")
# Display the CSV file records
print("Our DataFrame\n",df)
# Find and remove rows with NULL value
resdf = df.dropna()
# Return the new DataFrame
print("\nNew DataFrame (after removing rows with NULL)\n",resdf.to_string())
Output
Our DataFrame
Frequency Points
0 2.4 83.5
1 3.2 21.6
2 6.1 NaN
3 1.2 45.9
4 2.9 19.3
5 3.8 23.9
6 4.5 NaN
7 8.3 66.3
8 7.9 74.7
9 5.8 67.5
New DataFrame (after removing rows with NULL)
Frequency Points
0 2.4 83.5
1 3.2 21.6
3 1.2 45.9
4 2.9 19.3
5 3.8 23.9
7 8.3 66.3
8 7.9 74.7
9 5.8 67.5
Pandas fillna() method
The fillna() method in Pandas is used to replace NULL values with a specific value. Let us see an example:
import pandas as pd
# Input CSV file
df = pd.read_csv(r"C:\Users\hp\Desktop\demo.csv")
# Display the CSV file records
print("Our DataFrame\n",df)
# Find and replace NULL values with a specific value 111
resdf = df.fillna(111)
# Return the new DataFrame
print("\nNew DataFrame (after replacing NULL with a specific value)\n",resdf.to_string())
Output
Our DataFrame
Frequency Points
0 2.4 83.5
1 3.2 21.6
2 6.1 NaN
3 1.2 45.9
4 2.9 19.3
5 3.8 23.9
6 4.5 NaN
7 8.3 66.3
8 7.9 74.7
9 5.8 67.5
New DataFrame (after replacing NULL with a specific value)
Frequency Points
0 2.4 83.5
1 3.2 21.6
2 6.1 111.0
3 1.2 45.9
4 2.9 19.3
5 3.8 23.9
6 4.5 111.0
7 8.3 66.3
8 7.9 74.7
9 5.8 67.5
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others:
For Videos, Join Our YouTube Channel: Join Now
Read More:
No Comments