24 Sep Bagging vs Boosting in Machine Learning
Ensemble techniques improve prediction accuracy and robustness by combining the predictions of multiple models. Two of such techniques are Bagging and Boosting. Let us understand them one by one and also see their differences.
Bagging
In Bagging (Bootstrap Aggregation), multiple models are trained in parallel on different subsets of the data. The predictions are then averaged. Models are trained independently in parallel. Bagging is a technique in ensemble learning.
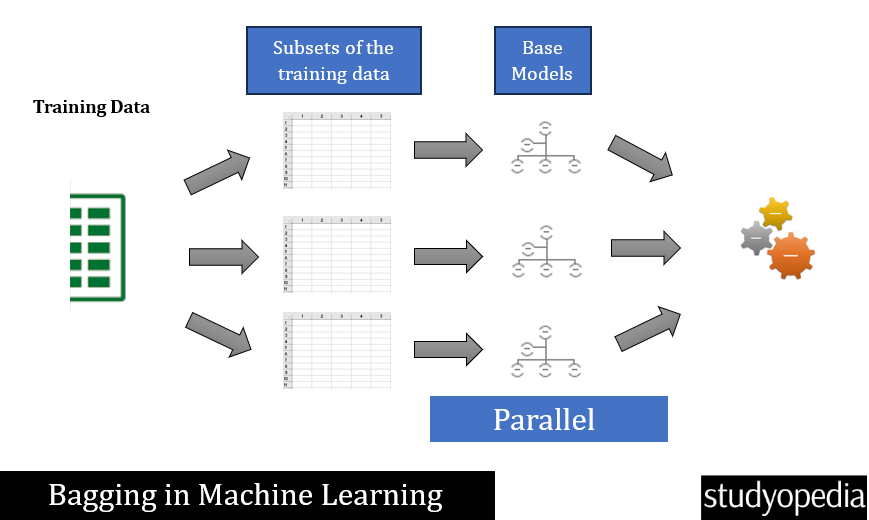
Boosting
Boosting (Iterative Learning) involves training models sequentially. Each new model focuses on correcting the errors of the previous ones. Models are trained sequentially, each correcting the previous. Boosting is also a technique in ensemble learning.
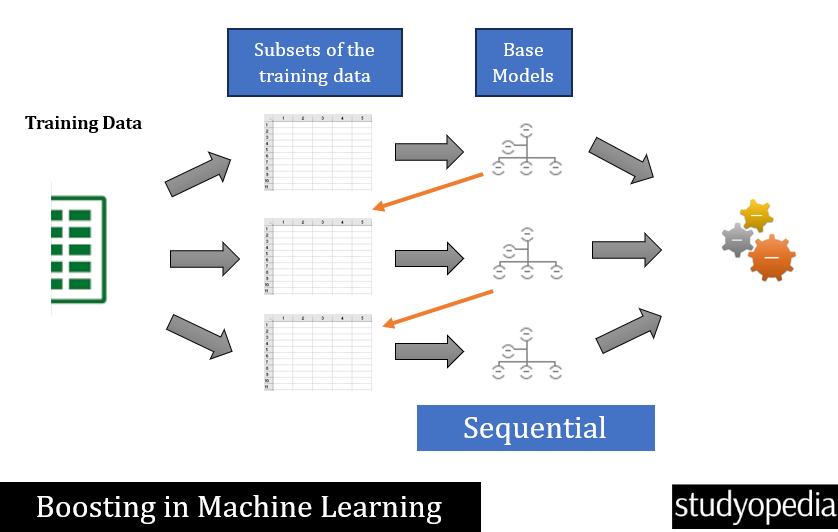
Differences between Bagging vs Boosting
Let us see the differences between Bagging and Boosting:
| Bagging | Boosting | |
|---|---|---|
| What | In Bagging, multiple models are trained in parallel on different subsets of the data. The predictions are then averaged. | In Boosting, each new model focuses on correcting the errors of the previous ones |
| Model Training | Trained independently in parallel | Trained sequentially, each correcting the previous model. |
| Data Sampling | Uses bootstrapping i.e. sampling with replacement | Uses all data, focusing on misclassified instances |
| Model Combination | Averaging i.e. regression or voting i.e. classification | Weighted combination based on model performance |
| Advantages | Reduces variance, robust to overfitting | Reduces both bias and variance, often highly accurate |
| Disadvantages | Does not reduce bias and requires more computational resources | Prone to overfitting if not regularized |
| Use Cases | Classification and regression tasks | Tasks requiring high accuracy and handling of complex data |
| Algorithms | Random Forest | AdaBoost, Gradient Boosting |
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
No Comments