03 Mar Text to Video Synthesis using Hugging Face
Text-to-video synthesis is an emerging field in AI that involves generating video content from textual descriptions. Hugging Face, a popular platform for natural language processing (NLP) and machine learning, provides access to various pre-trained models and tools that can be used for such tasks. While Hugging Face is primarily known for NLP models, it also supports integrations with other frameworks and libraries that can be used for video synthesis.
Before moving further, we’ve prepared a video tutorial to implement Text-to-Video with Hugging Face:
Text-to-video synthesis involves:
- Generating a sequence of frames (images) based on a textual description.
- Ensuring temporal consistency and coherence across frames.
This task is complex and often requires combining NLP models (for understanding text) with generative models like GANs (Generative Adversarial Networks) or diffusion models (for generating images/videos).
The following are the video generation frameworks:
- RunwayML: Offers tools for video generation and editing.
- Pika Labs: Specializes in AI-generated videos.
- DeepMind’s Perceiver IO: A model that can handle multimodal inputs (text, images, video).
Use libraries like PyTorch or TensorFlow to build custom pipelines for generating video frames and stitching them together.
Text-to-Video – Coding Example
The following is a step-by-step guide on how to use the Hugging Face Transformers library for text-to-video:
Step 1: Install Required Libraries
On Google Colab, use the following command to install:
|
1 2 3 |
!pip install transformers diffusers torch |
Step 2: Load a Text-to-Image Model
Use Hugging Face’s diffusers library to load a pre-trained text-to-image model like Stable Diffusion.
|
1 2 3 4 5 6 7 8 |
from diffusers import StableDiffusionPipeline import torch # Load the model pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16) pipe = pipe.to("cuda") |
Step 3: Generate Frames from Text
Generate individual frames based on the text description. This will generate 10 images:
|
1 2 3 4 5 6 7 |
prompt = "A futuristic cityscape at sunset" frames = [] for i in range(10): # Generate 10 frames frame = pipe(prompt).images[0] frames.append(frame) |
Step 4: Stitch Frames into a Video
Use a library like opencv or moviepy to stitch the frames into a video.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import cv2 import numpy as np # Save frames as images for i, frame in enumerate(frames): cv2.imwrite(f"frame_{i}.png", np.array(frame)) # Stitch frames into a video frame_rate = 5 frame_size = frames[0].size out = cv2.VideoWriter("output_video.mp4", cv2.VideoWriter_fourcc(*"mp4v"), frame_rate, frame_size) for i in range(len(frames)): frame = cv2.imread(f"frame_{i}.png") out.write(frame) out.release() |
The generated video will be saved as output_video.png in your working directory.
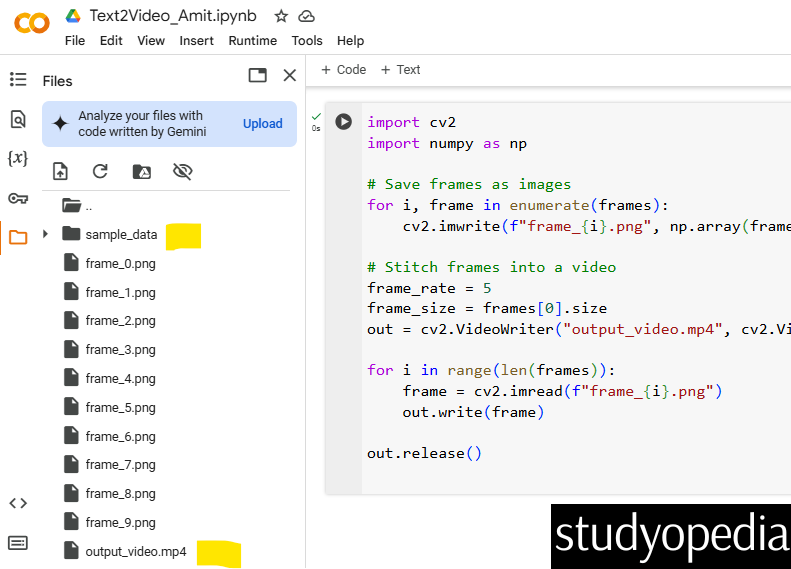
Right-click and click Download it to see the result of your text-to-video generation. The 10 images we generated in Step 3 are also visible:
The video generates successfully:
- The video will consist of a sequence of frames (images) generated based on the input text prompt.
- Each frame is generated using a text-to-image model (e.g., Stable Diffusion), and the frames are stitched together to create a video.
- The length of the video depends on the number of frames generated and the frame rate (frames per second, or FPS).
Here is one of the screenshots of the output video:

Key Characteristics of the Output
- Frame Quality:
- The quality of each frame depends on the text-to-image model used (e.g., Stable Diffusion generates high-quality, photorealistic or artistic images).
- However, since the frames are generated independently, there might be inconsistencies between them (e.g., sudden changes in object positions or lighting).
- Temporal Consistency:
- Without explicit temporal modeling, the video might lack smooth transitions between frames.
- Advanced models (e.g., video diffusion models) can improve temporal consistency by generating frames in a sequence-aware manner.
- Video Length:
- The length of the video depends on the number of frames and the frame rate. For example:
- 10 frames at 5 FPS = 2 seconds of video.
- 30 frames at 10 FPS = 3 seconds of video.
- The length of the video depends on the number of frames and the frame rate. For example:
- File Format:
- The output is typically saved as a video file (e.g., .mp4, .avi) using libraries like OpenCV or moviepy.
Challenges and Considerations
- Temporal Consistency: Ensuring smooth transitions between frames is a major challenge.
- Computational Resources: Video generation is resource-intensive and may require GPUs.
- Dataset Availability: High-quality datasets for text-to-video synthesis are limited.
Explore Existing Tools
If building from scratch is too complex, explore existing tools and platforms:
- RunwayML: Offers text-to-video capabilities.
- Pika Labs: Focuses on AI-generated videos.
- Hugging Face Spaces: Check for community-built demos and models.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- RAG Tutorial
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- ChatGPT Tutorial
No Comments