03 Mar Text to Text Generations (Translate) using Hugging Face
In this lesson, we will use the Hugging Face Transformers library for text-to-text (text2text) translation. Models like T5, BART, and MarianMT are well-suited for translation tasks. Below is a step-by-step guide to performing translation using the Hugging Face Transformers library.
Before moving further, we’ve prepared a video tutorial to implement Language Translation with Hugging Face:
Text-to-text models typically require a task prefix to specify the type of task (e.g., translation, summarization, etc.). For example, Text2Text generation includes:
- Translation: “translate English to Spanish: …”
- Summarization: “summarize: …”
- Question Answering: “question: … answer: …”
- Paraphrasing
- Sentiment Classification
Text2Text vs Text Generation
Let us also see the difference between text2text and text generation:
The TextGeneration class is typically used for autoregressive text generation, where the model generates text sequentially, one token at a time. This is commonly used for tasks like:
- Story generation
- Dialogue systems
- Open-ended text completion
The Text2TextGeneration class is used for sequence-to-sequence (seq2seq) tasks, where the model takes an input sequence and generates an output sequence. This is commonly used for tasks like:
- Translation
- Summarization
- Paraphrasing
- Question answering
Note: We will run the codes on Google Colab
Text2Text Translation – Coding Example
Here’s a step-by-step guide on how to use the Hugging Face Transformers library for text-to-text tasks:
Install the Required Libraries
Ensure you have the transformers and torch (or tensorflow) libraries installed. On Google Colab, use the following command to install:
!pip install transformers torch
Load a Pre-trained Translation Model
Hugging Face provides pre-trained models for translation tasks. For example:
- T5: A versatile text-to-text model that can handle translation by prefixing the input with a task-specific prompt (e.g., “translate English to French:”).
- MarianMT: A model specifically fine-tuned for translation tasks.
Here’s how to load a T5 model for translation:
from transformers import T5ForConditionalGeneration, T5Tokenizer # Load the pre-trained T5 model and tokenizer model_name = "t5-small" # You can use "t5-base", "t5-large", etc. tokenizer = T5Tokenizer.from_pretrained(model_name) model = T5ForConditionalGeneration.from_pretrained(model_name)
Prepare the Input Text
For translation tasks, you need to prefix the input text with a task-specific prompt. For example:
- English to Spanish: “translate English to Spanish: …”
- English to German: “translate English to German: …”
Here’s an example of translating English to Spanish:
input_text = "Translate English to Spanish: My name is Amit Diwan, and I love cricket."
Tokenize the Input Text
Tokenize the input text into input IDs that the model can process:
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
Generate the Translated Text
Use the model to generate the translated text. You can customize the generation process with parameters like max_length, num_beams, etc.
# Generate translation
outputs = model.generate(input_ids, max_length=50)
# Decode the output tokens to text
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Translated Text:", translated_text)
Example Output
For the input sentence:
Translate English to Spanish: My name is Amit Diwan, and I love cricket.
The output might look like after translating English to Spanish:
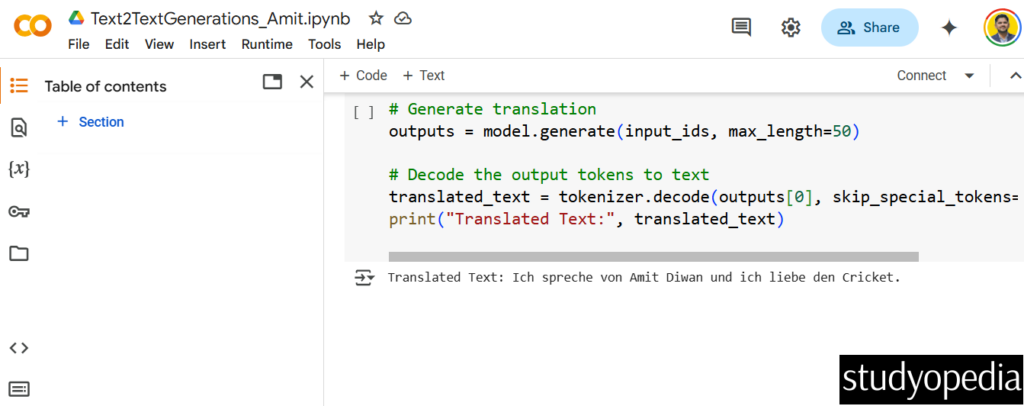
The above screenshot shows the following output:
Translated Text: Ich spreche von Amit Diwan und ich liebe den Cricket.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- RAG Tutorial
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- ChatGPT Tutorial
No Comments