03 Mar Text Summarizations using Hugging Face
The Hugging Face Transformers library is a powerful tool for natural language processing (NLP) tasks, including text summarization. Let us first see why summarization is useful.
Why Summarization
Summarization is useful in many real-world applications:
- News Aggregation: Summarizing long articles into short snippets.
- Document Summarization: Condensing lengthy reports or research papers.
- Chatbots: Providing concise responses to user queries.
- Content Curation: Extracting key points from large datasets.
Before moving further, we’ve prepared a video tutorial to implement Text Summarization with Hugging Face:
Note: We will run the codes on Google Colab
Text Summarizations – Coding Example
Below is a step-by-step guide on how to use the Transformers library for text summarization.
Step 1: Install the Required Libraries
First, ensure you have the transformers and torch (PyTorch) or TensorFlow libraries installed. You can install them using pip. On Google Colab, use the following command to install:
|
1 2 3 |
!pip install transformers torch # For PyTorch |
Step 2: Load a Pre-trained Summarization Model
Hugging Face provides pre-trained models specifically for summarization tasks. You can load a model and its corresponding tokenizer using the pipeline API or directly with AutoModelForSeq2SeqLM and AutoTokenizer.
Option 1: Using the pipeline API (Simplest Method)
The pipeline API abstracts away much of the complexity and is ideal for quick use. Here, are also providing the input text to summarize:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from transformers import pipeline # Load the summarization pipeline summarizer = pipeline("summarization") # Input text to summarize text = """ Virat Kohli is an Indian international cricketer known for his exceptional batting skills and leadership. He has played for the Indian national team in all formats and is a former captain. Kohli is often referred to as "King Kohli" and "Chase Master" due to his remarkable ability to chase down targets. """ # Generate a summary summary = summarizer(text, max_length=50, min_length=25, do_sample=False) print(summary[0]['summary_text']) |
Option 2: Using AutoModelForSeq2SeqLM and AutoTokenizer (More Control)
If you need more control over the process, you can load the model and tokenizer directly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer # Load a pre-trained model and tokenizer model_name = "facebook/bart-large-cnn" # Example model for summarization tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSeq2SeqLM.from_pretrained(model_name) # Input text to summarize text = """ Virat Kohli is an Indian international cricketer known for his exceptional batting skills and leadership. He has played for the Indian national team in all formats and is a former captain. Kohli is often referred to as "King Kohli" and "Chase Master" due to his remarkable ability to chase down targets. """ # Tokenize the input text inputs = tokenizer.encode("summarize: " + text, return_tensors="pt", max_length=512, truncation=True) # Generate the summary summary_ids = model.generate(inputs, max_length=50, min_length=25, length_penalty=2.0, num_beams=4, early_stopping=True) summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True) print(summary) |
Step 3: Customize the Summarization
You can adjust parameters to control the summary’s length and quality. Here are the parameters we used above:
- max_length:
- The maximum number of tokens in the summary.
- Example: max_length=50 ensures the summary is no longer than 50 tokens.
- min_length:
- The minimum number of tokens in the summary.
- Example: min_length=25 ensures the summary is at least 25 tokens long.
- num_beams:
- Controls the beam search width. Higher values improve quality but slow down inference.
- Example: num_beams=4 uses 4 beams for decoding.
- length_penalty:
- Encourages longer or shorter summaries.
- Example: length_penalty=2.0 favors longer summaries.
- do_sample:
- If True, the model uses sampling instead of greedy decoding, which can produce more diverse summaries.
Example Output
For the input text provided above, the output might look like this. The output is the summarized version of the input text. It is a shorter version of the input that captures the key points or main ideas:
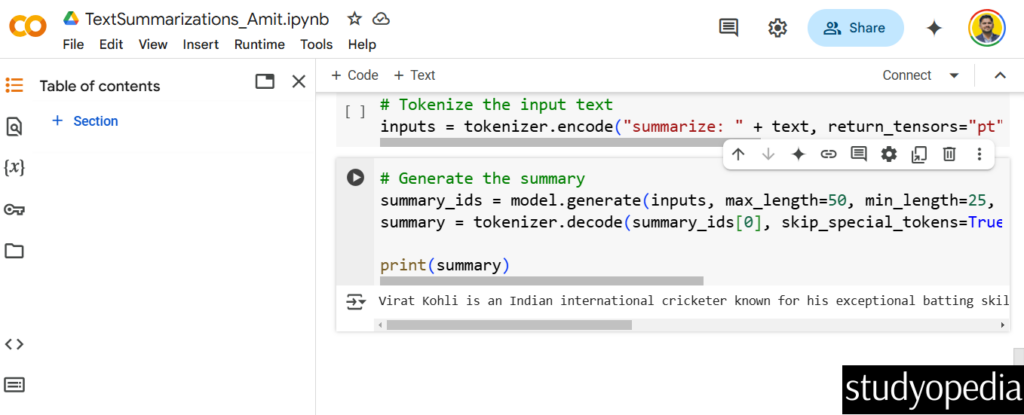
The following is the output as shown in the above output:
|
1 2 3 4 |
Virat Kohli is an Indian intermational cricketer known for his batting skills and leadership. He is often referred to as "King Kohli" and "Chase Master" for his ability to chase targets. |
Above, the input was a raw text that you want to summarize. This could be a long article, a paragraph, or even a document. The goal of summarization is to condense this input text into a shorter version while retaining the most important information. As we saw, this was our input text:
|
1 2 3 4 5 |
Virat Kohli is an Indian international cricketer known for his exceptional batting skills and leadership. He has played for the Indian national team in all formats and is a former captain. Kohli is often referred to as "King Kohli" and "Chase Master" due to his remarkable ability to chase down targets. |
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- RAG Tutorial
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- ChatGPT Tutorial
No Comments