03 Mar Text Classification using Hugging Face
In this lesson, we will learn how to use the Hugging Face Transformers library for text classification, specifically for the spam detection example. Text classification can be applied to use cases, such as:
- Spam Detection: Classify emails or messages as SPAM or NOT SPAM.
- Topic Classification: Classify news articles or documents into topics like SPORTS, POLITICS, TECHNOLOGY, etc.
- Intent Detection: Classify user queries into intents like BOOK_FLIGHT, CANCEL_ORDER, CHECK_BALANCE, etc.
Before moving further, we’ve prepared a video tutorial to implement Text Classification with Hugging Face:
Note: We will run the codes on Google Colab
Text Classification vs Sentiment Analysis
Let us also see the difference between Text Classification and Sentiment Analysis:
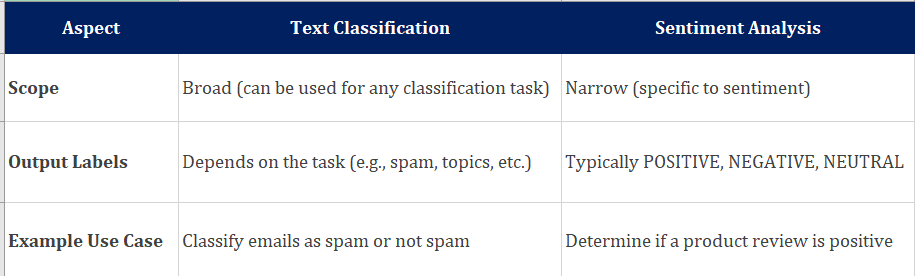
Text Classification – Coding Example
Let us see how to use the Hugging Face Transformers library for text classification, specifically for the spam detection example. We’ll use a pre-trained model fine-tuned for spam detection and demonstrate how to classify texts as SPAM or NOT SPAM.
Step 1: Install the Required Libraries
First, install the Hugging Face Transformers library and other dependencies. On Google Colab, use the following command to install:
!pip install transformers !pip install torch
Step 2: Import the Necessary Modules
Import the required modules from the Transformers library:
from transformers import pipeline
Step 3: Load a Pre-trained Spam Detection Model
We’ll use a pre-trained model fine-tuned for spam detection. For this example, we’ll use the philschmid/distilbert-base-multilingual-cased-sentiment model from the Hugging Face Model Hub.
spam_classifier = pipeline("text-classification", model="philschmid/distilbert-base-multilingual-cased-sentiment")
Step 4: Perform Spam Detection
Now that we have loaded the spam detection pipeline, we can use it to classify texts as SPAM or NOT SPAM.
Classify multiple texts at once by passing a list of strings:
texts = [
"Congratulations! You've won a 500 INR Amazon gift card. Click here to claim now.",
"Hi Amit, let's have a meeting tomorrow at 12 PM.",
"URGENT: Your gmail account has been compromised. Click here to secure it."
]
results = spam_classifier(texts)
Step 5: Map Labels to SPAM and NOT SPAM
label_mapping = {'negative': 'SPAM', 'neutral': 'NOT SPAM', 'positive': 'NOT SPAM'}
Display the result:
for result in results:
label = label_mapping[result['label']] # Map the label
score = result['score']
print(f"Label: {label}, Confidence: {score:.4f}")
Output
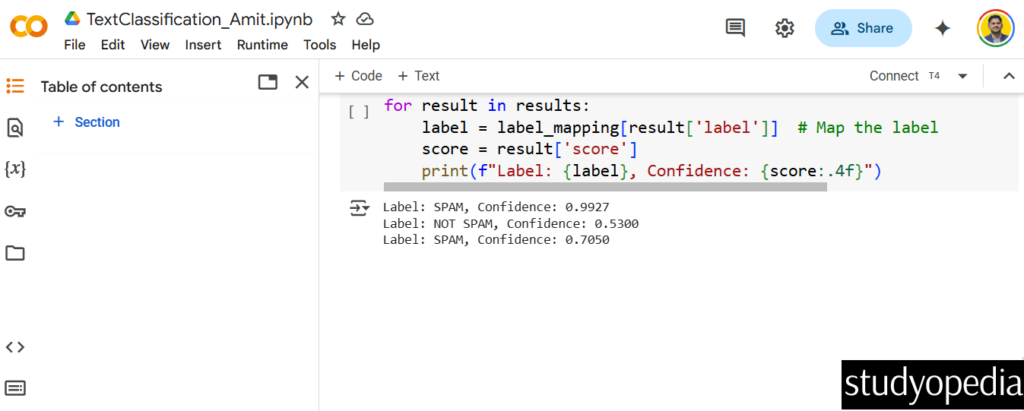
The following is the output as shown in the above screensh0t:
Label: SPAM, Confidence: 0.9927 Label: NOT SPAM, Confidence: 0.5300 Label: SPAM, Confidence: 0.7050
The first and third texts are classified as SPAM, while the second text is classified as NOT SPAM.
The model is now classifying the texts as SPAM or NOT SPAM, but the confidence scores for some predictions are relatively low (e.g., 0.5300 and 0.7050). This indicates that the model is uncertain about some of its predictions. The following can be the reasons:
- Model Limitations:
- The philschmid/distilbert-base-multilingual-cased-sentiment model is fine-tuned for sentiment analysis, not specifically for spam detection. While we can adapt it for spam detection by mapping negative to SPAM and neutral/positive to NOT SPAM, the model might not perform well on spam detection tasks because it was trained on a different type of data (sentiment analysis).
- Text Formatting:
- The input texts might need preprocessing (e.g., cleaning, lowercasing) to match the format expected by the model.
- Confidence Scores:
- Low confidence scores (e.g., below 0.7) indicate that the model is uncertain about its predictions.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- RAG Tutorial
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- ChatGPT Tutorial
No Comments