03 Mar Sentiment Analysis using Hugging Face
The Hugging Face Transformers library is a powerful tool for natural language processing (NLP) tasks, including sentiment analysis. Sentiment analysis involves determining the sentiment (positive, negative, or neutral) expressed in a piece of text.
Before moving further, we’ve prepared a video tutorial to implement Sentiment Analysis with Hugging Face:
Types of Sentiment Analysis
- Polarity Detection
- Classifies text as Positive, Negative, or Neutral.
- Example:
- “I love this product!” → Positive
- “This service is terrible.” → Negative
- “The package arrived on time.” → Neutral
- Emotion Detection
- Identifies specific emotions (e.g., happiness, frustration, surprise).
- Example:
- “I’m thrilled about the results!” → Joy
- “This is so frustrating!” → Anger
- Aspect-Based Sentiment Analysis
- Analyzes sentiment toward specific aspects of a product/service.
- Example (for a restaurant review):
- “The food was great, but the service was slow.”
- Food → Positive
- Service → Negative
- “The food was great, but the service was slow.”
- Intent Analysis
- Detects whether the writer intends to purchase, complain, inquire, etc.
- Example:
- “Where can I buy this?” → Purchase intent
Sentiment Analysis – Coding Example
The following is a step-by-step guide on how to use the Hugging Face Transformers library for sentiment analysis.
Note: We have used the distilbert-base-uncased-finetuned-sst-2-english model which is publicly available on Hugging Face. It can be accessed without using the Hugging Face API by downloading the model files and using them locally.
Note: We will run the code on Google Colab
On Google Colab, it is suggested to enable GPU Acceleration (Optional). Google Colab provides free access to GPUs, which can significantly speed up your computations. To enable GPU:
- Click on Runtime → Change runtime type.
- Select GPU under Hardware accelerator.
- Click Save.
Here are the steps with the code:
Step 1: Install the Required Libraries
First, you need to install the Hugging Face Transformers library and other dependencies. You can do this using pip. On Google Colab, use the following command to install:
|
1 2 3 4 |
!pip install transformers !pip install torch |
Step 2: Import the Necessary Modules
Next, import the necessary modules from the Transformers library:
|
1 2 3 |
from transformers import pipeline |
Step 3: Load the Sentiment Analysis Pipeline
The pipeline function in the Transformers library provides a simple way to perform various NLP tasks, including sentiment analysis. You can load a pre-trained sentiment analysis model as follows:
|
1 2 3 |
sentiment_analyzer = pipeline("sentiment-analysis") |
This will load a default pre-trained model for sentiment analysis. If you want to use a specific model, you can specify it:
|
1 2 3 |
sentiment_analyzer = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") |
Step 4: Perform Sentiment Analysis
Now that you have loaded the sentiment analysis pipeline, you can use it to analyze the sentiment of a piece of text:
|
1 2 3 4 5 |
text = "I love playing and watching cricket!" result = sentiment_analyzer(text) print(result) |
The output will be a list of dictionaries, where each dictionary contains the sentiment label (label) and the confidence score (score):
|
1 2 3 |
[{'label': 'POSITIVE', 'score': 0.9998760223388672}] |
Step 5: Analyze Multiple Texts
You can also analyze multiple texts at once by passing a list of strings to the sentiment analyzer:
|
1 2 3 4 5 6 7 8 9 |
texts = [ "I love playing and watching cricket!", "I hate when Virat Kohli misses a century." ] results = sentiment_analyzer(texts) for result in results: print(result) |
The output will be a list of results, one for each input text:
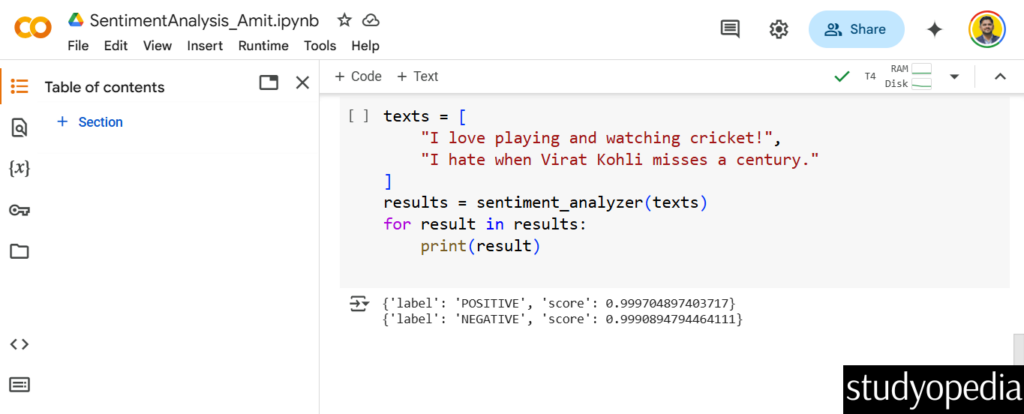
The above output screenshot displays our output is the following:
|
1 2 3 4 |
{'label': 'POSITIVE', 'score': 0.999704897403717} {'label': 'NEGATIVE', 'score': 0.9990894794464111} |
The score in the output of the Hugging Face sentiment analysis pipeline represents the confidence level or probability that the model assigns to the predicted sentiment label. It indicates how confident the model is that the given text corresponds to the predicted sentiment. Here is the explanation:
- The score is a value between 0 and 1.
- A score closer to 1 means the model is very confident in its prediction.
- A score closer to 0 means the model is less confident in its prediction.
Let us understand the output:
The label POSITIVE indicates that the model predicts the sentiment of the text is positive. The score 0.999704897403717 means the model is 99.97% confident that the sentiment is positive.
|
1 2 3 |
{'label': 'POSITIVE', 'score': 0.9999704897403717} |
The label NEGATIVE indicates that the model predicts the sentiment of the text is negative. The score 0.9990894794464111 means the model is 99.90% confident that the sentiment is negative.
|
1 2 3 |
{'label': 'NEGATIVE', 'score': 0.9991121292114258} |
Why Is the Score So High (Close to 1)?
- Pre-trained Models: The model you’re using (e.g., distilbert-base-uncased-finetuned-sst-2-english) has been fine-tuned on a large dataset (like SST-2, the Stanford Sentiment Treebank) and is highly accurate for sentiment analysis tasks.
- Clear Sentiment: The input text likely contains strong, unambiguous language that makes it easy for the model to predict the sentiment with high confidence.
For example, a sentence like “I hate this product, it’s the worst!” would likely result in a high confidence score for NEGATIVE.
How to Interpret the Score
Here’s how to interpret the score in practical terms:
- Close to 1 (e.g., 0.99):
- The model is very confident in its prediction.
- The sentiment expressed in the text is likely clear and unambiguous.
- Example: 0.9990894794464111 means the model is 99.90% confident the sentiment is NEGATIVE.
- Around 0.5-0.7:
- The model is less confident in its prediction.
- The sentiment might be ambiguous or the text might contain mixed emotions.
- Example: A score of 0.6 for POSITIVE means the model is only 60% confident the sentiment is positive.
- Close to 0 (e.g., 0.1):
- The model is very uncertain about its prediction.
- The text might be neutral, complex, or contain conflicting sentiments.
- Example: A score of 0.1 for NEGATIVE means the model is only 10% confident the sentiment is negative.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- RAG Tutorial
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- ChatGPT Tutorial
No Comments