14 May Naive Bayes Algorithm
Naive Bayes is a supervised learning algorithm. It is a probabilistic machine learning algorithm based on Bayes’ Theorem with an assumption of independence among predictors (features). It is primarily used for classification tasks, not regression. In this lesson, we will learn:
- Features of Naive Bayes
- Types of Naive Bayes Algorithms
- Advantages of Naive Bayes Algorithms
- Disadvantages of Naive Bayes Algorithms
- Example: Spam Email Classification with Naive Bayes
Features of Naive Bayes
The following are the features of the Naive Bayes algorithm:
- Probabilistic Model: Calculates the probability of a data point belonging to a class.
- “Naive” Assumption: Assumes features are independent of each other (though this is rarely true in real-world data).
- Fast & Efficient: Works well even with large datasets.
- Low Computational Cost: Requires less training time compared to complex models.
- Works Well with High-Dimensional Data: Such as text classification (e.g., spam detection).
Types of Naive Bayes Algorithms
The following are the types of the Naive Bayes algorithm:
- Gaussian Naive Bayes: Assumes continuous features follow a normal distribution.
- Multinomial Naive Bayes: Used for discrete counts (e.g., text classification with word frequencies).
- Bernoulli Naive Bayes: For binary/boolean features (e.g., presence/absence of words).
Advantages of Naive Bayes Algorithms
The following are the advantages of the Naive Bayes algorithm:
- Simple & easy to implement
- Performs well with small datasets
- Handles High-Dimensional data well (e.g., NLP tasks)
- Less prone to Overfitting (due to simplicity)
- Works well with Categorical features
Disadvantages of Naive Bayes Algorithms
The following are the disadvantages of the Naive Bayes algorithm:
- Strong Independence Assumption (Features are rarely independent in reality)
- Zero-Frequency Problem: If a category in test data was not seen in training, it assigns zero probability (can be fixed using smoothing techniques).
- Not Suitable for Complex Relationships (Performs poorly if features are highly correlated)
Example: Spam Email Classification
Let us see the Naive Bayes Python Implementation example:
- Problem: Classify emails as “Spam” (1) or “Not Spam” (0) based on words.
- What we’ll do: We’ll use the scikit-learn library to implement Naive Bayes for spam email classification.
- Dataset Used: We’ll create a simple dataset with emails and labels (0 = Not Spam, 1 = Spam).
Steps:
- Import Libraries
- Prepare Dataset (Text → Numerical Features using
CountVectorizer) - Train-Test Split
- Train Naive Bayes Model (MultinomialNB)
- Evaluate Model (Accuracy, Confusion Matrix)
Here are the steps with the code snippets:
Step 1: Import Required Libraries
import numpy as np from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.3, random_state=42)
Step 5. Train the Naive Bayes Model
model = MultinomialNB() model.fit(X_train, y_train)
Step 6. Make Predictions & Evaluate Model
y_pred = model.predict(X_test)
# Accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Confusion Matrix
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
# Classification Report
print("Classification Report:\n", classification_report(y_test, y_pred))
Output till now:
Accuracy: 1.0 # Perfect classification in this small example
Confusion Matrix:
[[1 0]
[0 1]]
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 1
1 1.00 1.00 1.00 1
Step 7. Test on a New Email
new_email = ["Free gift for you"]
new_email_features = vectorizer.transform(new_email)
prediction = model.predict(new_email_features)
print("Prediction (0=Not Spam, 1=Spam):", prediction)
Complete Output
The following is the output. We ran the code on Google Colab:
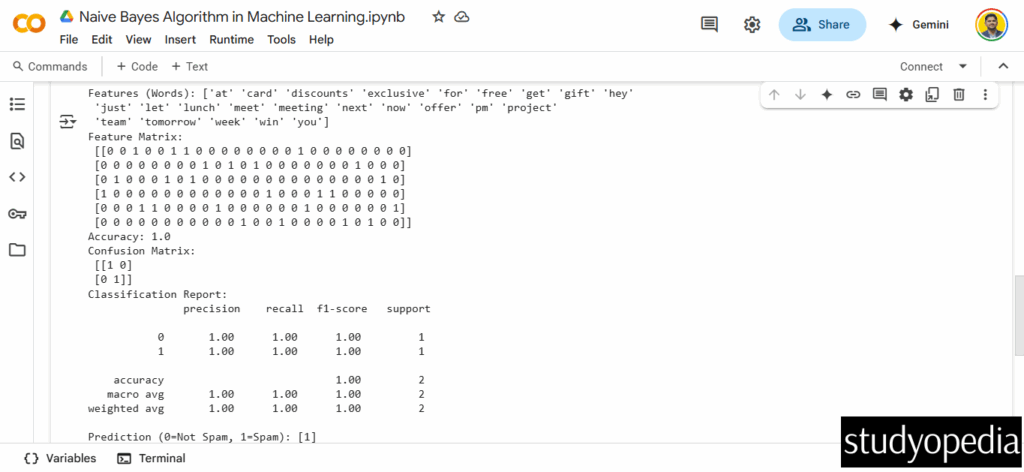
The above screenshot shows the output is:
Prediction (0=Not Spam, 1=Spam): [1] # Correctly classified as Spam
Key Takeaways from the Code
- Text Preprocessing:
CountVectorizerconverts text into word counts. - MultinomialNB: Best for discrete word counts (text classification).
- High Accuracy: Works well even with small datasets.
- Real-World Use Case: Used in spam filters, sentiment analysis, and document categorization.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
No Comments