16 May Decision Tree in Machine Learning
A Decision Tree is a supervised learning algorithm used for both classification and regression tasks in machine learning. It creates a model that predicts the value of a target variable by learning simple decision rules inferred from the data features.
Decision trees are a supervised learning method because they require labeled training data to learn the decision rules. Decision trees can be used for:
- Classification: When the target variable is categorical (e.g., spam/not spam)
- Regression: When the target variable is continuous (e.g., house price)
How Decision Trees Work
Let us see how decision trees work:
- The algorithm starts at the root node (top of the tree)
- It splits the data based on the feature that provides the most information gain (or Gini impurity reduction for classification, variance reduction for regression)
- This process repeats recursively until:
- All leaf nodes contain samples of a single class (classification)
- A stopping criterion is met (e.g., maximum depth)
- No further splits provide meaningful information gain
Features of Decision Trees
The following are the features of decision trees:
- Non-parametric: Doesn’t make assumptions about data distribution
- White box model: Easy to interpret and visualize
- Handles both numerical and categorical data
- Automatic feature selection: Uses most important features near root
Advantages of Decision Trees
The following are the advantages of decision trees:
- Easy to understand and interpret (can be visualized)
- Requires little data preprocessing (no need for feature scaling)
- Can handle both numerical and categorical data
- Models non-linear relationships
- Performs automatic feature selection
Disadvantages of Decision Trees
The following are the disadvantages of decision trees:
- Prone to overfitting, especially with complex trees
- Unstable (small changes in data can lead to different trees)
- Biased towards features with more levels
- Not ideal for XOR-like problems
- Can create biased trees if some classes dominate
Applications
The following are the applications of decision trees:
- Customer churn prediction
- Credit risk assessment
- Medical diagnosis
- Fraud detection
- Recommendation systems
- Quality control in manufacturing
Example 1: Decision Tree for Classification with Python
Objective: Classify iris flowers into species (setosa, versicolor, virginica) based on features like petal length, sepal width, etc.
In the below example, we will predict discrete classes (e.g., iris species). Here are the steps:
Step 1: Import the required libraries
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, confusion_matrix import matplotlib.pyplot as plt from sklearn.tree import plot_tree
Step 2: Load dataset
iris = load_iris() X = iris.data y = iris.target
Step 3: Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Step 4: Create and train classifier
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42) clf.fit(X_train, y_train)
Step 5: Predict and evaluate
y_pred = clf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred):.2f}")
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
Step 6: Visualize the tree
plt.figure(figsize=(12,8)) plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True) plt.show()
Output
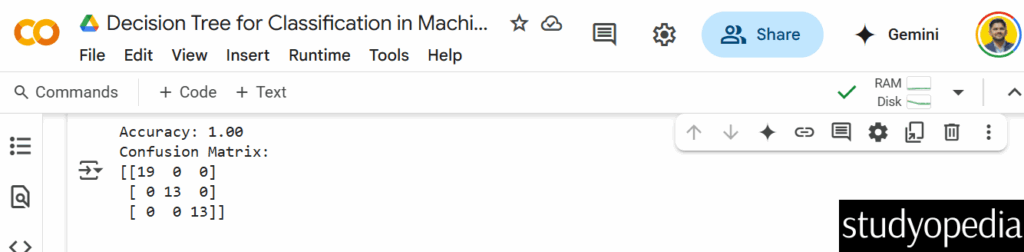
Here is the decision tree:
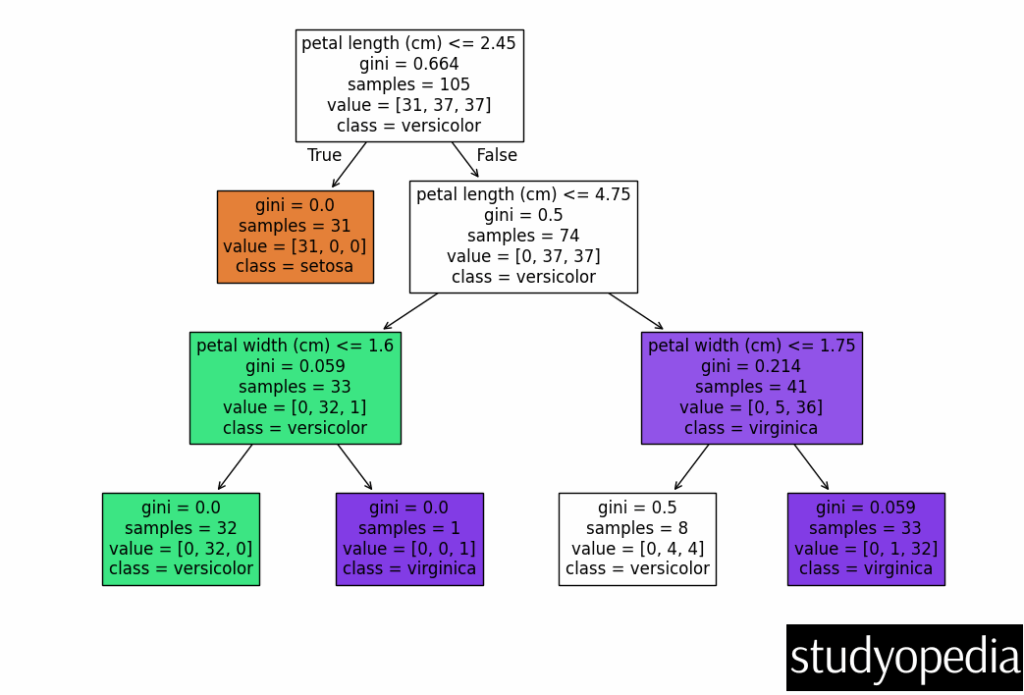
What We Achieved:
- Trained a Decision Tree to classify iris flowers.
- Evaluated performance using accuracy and confusion matrix.
- Visualized the tree to understand decision rules.
Example 2: Decision Tree for Regression with Python
Objective: Predict diabetes progression (a continuous value) based on features like age, BMI, blood pressure, etc.
In the below example, we will predict continuous values (e.g., diabetes progression). Here are the steps:
Step 1: Import the required libraries
from sklearn.datasets import load_diabetes from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score import matplotlib.pyplot as plt from sklearn.tree import plot_tree
Step 2: Load dataset
diabetes = load_diabetes() X = diabetes.data y = diabetes.target
Step 3: Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Step 4: Create and train regressor
reg = DecisionTreeRegressor(criterion='squared_error', max_depth=3, random_state=42) reg.fit(X_train, y_train)
Step 5: Predict and evaluate
y_pred = reg.predict(X_test)
print(f"MSE: {mean_squared_error(y_test, y_pred):.2f}")
print(f"R2 Score: {r2_score(y_test, y_pred):.2f}")
Step 6: Visualize the tree
plt.figure(figsize=(12,8)) plot_tree(reg, feature_names=diabetes.feature_names, filled=True) plt.show()
Output
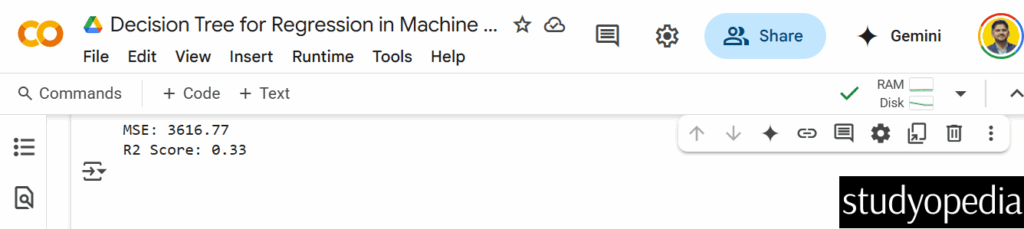
Here is the decision tree:
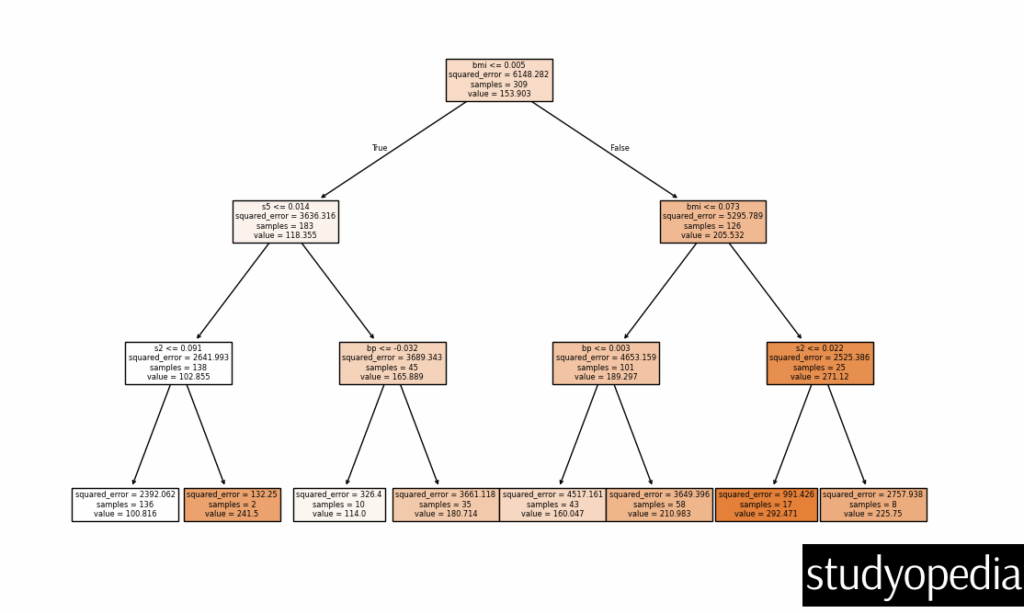
What We Achieved:
- Trained a Decision Tree to predict diabetes progression.
- Evaluated performance using Mean Squared Error (MSE) and R² Score.
- Visualized the tree to see how splits affect predictions.
Key Parameters
- criterion:
- Classification: “gini” or “entropy”
- Regression: “squared_error”, “friedman_mse”, etc.
- max_depth: Maximum depth of the tree
- min_samples_split: Minimum samples required to split a node
- min_samples_leaf: Minimum samples required at a leaf node
- max_features: Number of features to consider for best split
Tips for Better Performance
- Prune trees to avoid overfitting (limit max_depth)
- Use ensemble methods like Random Forest which combine multiple trees
- Balance your dataset if classes are imbalanced
- Perform feature scaling (though not strictly necessary)
- Use cross-validation to find optimal parameters
Decision trees form the foundation for more advanced algorithms like Random Forests and Gradient Boosted Trees, making them an essential concept in machine learning.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
No Comments