01 Mar LangChain with RAG – Process
We saw the LangChain with RAG workflow in the previous lesson. Let us see the steps to implement LangChain with RAG. This is following the LangChain components. We have also added the relevant code.
Document Loaders
Document loaders are responsible for loading data from various sources (e.g., PDFs, databases, web pages) into a format that LangChain can process. We have used the PyPDFLoader is used to load PDF documents.
Where Does It Fit?
- Document loaders are part of the data preprocessing pipeline and are often used in conjunction with Indexes and Chains.
- They are not a standalone core component but are closely tied to Indexes (since the loaded documents are indexed in the vector store) and Chains (since the documents are used in the QA chain).
Here is the relevant code:
|
1 2 3 4 |
loader = PyPDFLoader(pdf_path) documents = loader.load() |
Text Splitters
Text splitters are used to break down large documents into smaller chunks that can be processed by LLMs or indexed efficiently. We have used the RecursiveCharacterTextSplitter is used to split documents into chunks.
Where Does It Fit?
- Text splitters are also part of the data preprocessing pipeline and are closely tied to Indexes (since the chunks are indexed in the vector store) and Chains (since the chunks are retrieved and used in the QA chain).
- They are not a standalone core component but are essential for preparing data for downstream tasks.
Here is the relevant code:
|
1 2 3 4 |
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) self.document_chunks = text_splitter.split_documents(self.documents) |
Models
This component refers to the language models (LLMs) or embedding models used in the system.
- Embedding Model: The HuggingFaceEmbeddings class is used to set up the embedding model (sentence-transformers/all-MiniLM-L6-v2).
- LLM: The HuggingFacePipeline class is used to set up the local LLM (google/flan-t5-base).
Here is the relevant code:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def setup_embeddings(self, model_name="sentence-transformers/all-MiniLM-L6-v2"): """Set up the embedding model.""" self.embeddings = HuggingFaceEmbeddings(model_name=model_name) def setup_local_llm(self, model_id="google/flan-t5-base", device="auto"): """Set up a local LLM using Hugging Face.""" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForSeq2SeqLM.from_pretrained(model_id, device_map=device) pipe = pipeline("text2text-generation", model=model, tokenizer=tokenizer, max_new_tokens=512, temperature=0.7) self.llm = HuggingFacePipeline(pipeline=pipe) |
Prompts
This component refers to the input queries or prompts used to interact with the LLM.
- The answer_question method takes a question as input, which acts as the prompt for the QA chain.
Here is the relevant code:
|
1 2 3 4 5 6 |
def answer_question(self, question): """Answer a question using the RAG system.""" answer = self.qa_chain.run(question) return answer |
Memory
This component refers to the storage of intermediate data or context. In this implementation, memory is not explicitly used, but the vector_store and document_chunks can be considered as part of memory.
Here is the relevant code:
|
1 2 3 |
self.vector_store = FAISS.from_documents(self.document_chunks, self.embeddings) |
Chains
This component refers to the sequence of operations or workflows. The RetrievalQA chain is used to combine the retriever (vector store) and the LLM.
Here is the relevant code:
|
1 2 3 4 5 6 7 8 9 |
def setup_qa_chain(self, k=3): """Create a QA chain using the vector store and LLM.""" self.qa_chain = RetrievalQA.from_chain_type( llm=self.llm, chain_type="stuff", retriever=self.vector_store.as_retriever(search_kwargs={"k": k}) ) |
Indexes
This component refers to the indexing of documents for efficient retrieval. The FAISS vector store is used to index the document chunks.
Here is the relevant code:
|
1 2 3 4 5 |
def create_vector_store(self): """Create a vector store from the document chunks.""" self.vector_store = FAISS.from_documents(self.document_chunks, self.embeddings) |
Agents
This component refers to the decision-making entity that interacts with the system. In this implementation, there is no explicit agent, but the LocalRAGSystem class itself acts as a high-level agent orchestrating the workflow.
Here is the relevant code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
class LocalRAGSystem: def __init__(self): self.documents = [] self.vector_store = None self.embeddings = None self.llm = None self.qa_chain = None def run_setup(self, chunk_size=1000, chunk_overlap=200, model_id="google/flan-t5-base", k=3): """Run the complete setup process.""" pdf_paths = self.upload_pdfs() self.load_documents(pdf_paths) self.split_documents(chunk_size=chunk_size, chunk_overlap=chunk_overlap) self.setup_embeddings() self.create_vector_store() self.setup_local_llm(model_id=model_id) self.setup_qa_chain(k=k) |
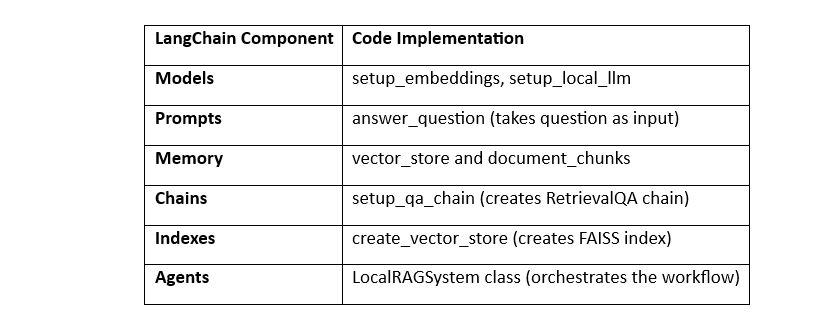
This is what we did above:
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- RAG Tutorial
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- ChatGPT Tutorial
No Comments