20 May Natural Language Processing using Python – Example
In this lesson, we will see a practical example of implementing NLP with Python. This example incorporates several of the concepts we’ve learned, including tokenization, text normalization, stemming/lemmatization, and a bag of words.
Read More: Python Free Tutorial
Example: Movie Review Sentiment Analysis with NLP
import nltk from nltk.corpus import movie_reviews from nltk.tokenize import word_tokenize from nltk.stem import WordNetLemmatizer from nltk.corpus import stopwords from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import accuracy_score, classification_report import random
Step 2: Download required NLTK data
nltk.download(['movie_reviews', 'punkt', 'stopwords', 'wordnet', 'omw-1.4'])
Step 3: Initialize tools
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
tokens = word_tokenize(text.lower())
processed_tokens = [
lemmatizer.lemmatize(token)
for token in tokens
if token.isalpha() and token not in stop_words
]
return ' '.join(processed_tokens)
Step 4: Prepare balanced dataset
positive_ids = movie_reviews.fileids('pos')
negative_ids = movie_reviews.fileids('neg')
positive_reviews = [preprocess_text(' '.join(movie_reviews.words(fileid))) for fileid in positive_ids]
negative_reviews = [preprocess_text(' '.join(movie_reviews.words(fileid))) for fileid in negative_ids]
Step 5: Combine and label (1 for positive, 0 for negative)
all_reviews = positive_reviews + negative_reviews labels = [1]*len(positive_reviews) + [0]*len(negative_reviews)
Step 6: Shuffle the data
combined = list(zip(all_reviews, labels)) random.shuffle(combined) all_reviews, labels = zip(*combined)
Step 7: Use TF-IDF instead of simple Bag of Words
vectorizer = TfidfVectorizer(max_features=2000) X = vectorizer.fit_transform(all_reviews) y = labels
Step 8: Split data properly (80% train, 20% test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 9: Train classifier
classifier = MultinomialNB() classifier.fit(X_train, y_train)
Step 10: Evaluate
y_pred = classifier.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred):.2f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
Step 11: Example predictions
test_samples = [
"This movie was fantastic! The acting was great and the plot was engaging.",
"The film was terrible. I hated every minute of it.",
"It was okay, not great but not awful either."
]
for review in test_samples:
processed = preprocess_text(review)
vector = vectorizer.transform([processed])
prediction = classifier.predict(vector)
print(f"\nReview: {review}")
print(f"Prediction: {'Positive' if prediction[0] == 1 else 'Negative'}")
Output
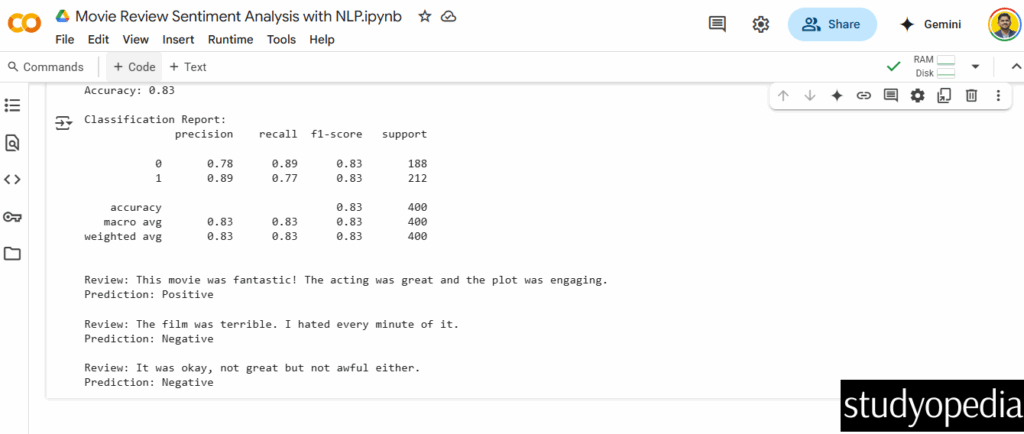
Key Concepts Demonstrated:
-
Text Normalization: Converting text to lowercase
-
Tokenization: Breaking text into words/tokens
-
Stopword Removal: Filtering out common words
-
Stemming/Lemmatization: Reducing words to base forms
-
Bag of Words: Creating numerical feature vectors from text
-
Sentiment Analysis: Classifying text as positive/negative
This example shows a complete pipeline from raw text to a working sentiment analysis model, incorporating many of the NLP concepts you’ve studied.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- Generative AI Tutorial
- Machine Learning Tutorial
- Deep Learning Tutorial
- Ollama Tutorial
- Retrieval Augmented Generation (RAG) Tutorial
- Copilot Tutorial
- Gemini Tutorial
- ChatGPT Tutorial
No Comments