13 Oct Process of Retrieval Augmented Generation (RAG)
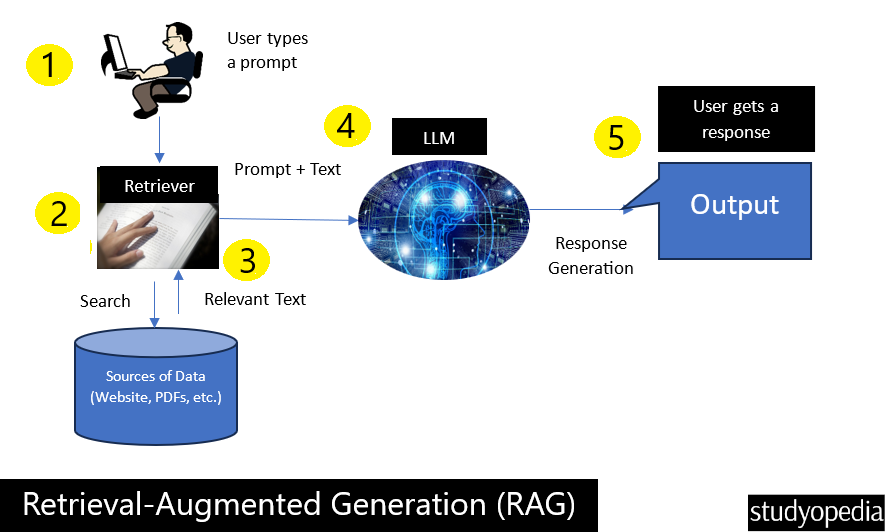
The process of RAG includes document retrieval, ranking them based on relevance, etc. The figure demonstrates the process of RAG to retrieve and generate when a user types a prompt.
In this figure, consider the Relevant Text above as relevant documents that are further sent with the prompt query to the LLM. You can also consider Sources of Data in the figure as a specific knowledge base. Therefore, RAG enhances LLM with specific data as well.
In the RAG process, vectors (or embeddings) are mathematical representations of data. The data can be both structured and unstructured.
Here is the process:
- Input Query: The user starts with a query or input question.
- Document Retrieval: The 2nd step includes:
Initial Search: The system searches through a large dataset to retrieve relevant documents or pieces of information based on the input query.
Chunking: These documents are divided into smaller pieces or chunks, making it easier to process and
retrieve the most relevant information. - Vector Embeddings: Embeddings are the backbone of the RAG process, allowing for efficient retrieval and meaningful generation of content. The chunks are then transformed into vector embeddings, which are numerical representations that capture the meaning of the text.
Encoding:
For example, the sentence “How to learn Java?” might be encoded into a vector like [0.1, 0.6, 0.2, …].
Query Encoding: The input query is encoded into a dense vector representation using models like BERT or other transformers.
Document Encoding: The retrieved documents are also encoded into dense vector representations.
Similarity Calculation:
These vectors allow the system to calculate similarities between the input query and potential information sources, ensuring relevant information is retrieved.
Cosine Similarity: Calculate the cosine similarity between the query vector and each document vector to
determine relevance.
Selection:
Top-k Selection: Select the top-k most relevant document embeddings based on the similarity scores.
- Relevance Ranking: The retrieved and encoded document chunks are ranked according to their relevance to the query, using
various ranking algorithms. - Context Encoding: Both the query and the top-k selected document embeddings are encoded together to form a context vector.
- Attention Mechanism: The model uses an attention mechanism to focus on the most relevant parts of the encoded context,
ensuring that the generated response is contextually accurate. - Response Generation:
Generative Model: A generative model, often based on LLMs like GPT, uses the encoded context to generate a coherent and contextually appropriate response. LLMs are adept at understanding and generating human-like text, making them ideal for this step.
Example: The model generates a detailed response about the Taj Mahal’s history, architectural significance, and cultural impact. - Output: The final generated response is provided to the user, incorporating both the retrieved and generated
information.
Let us now see an example of RAG.
If you liked the tutorial, spread the word and share the link and our website Studyopedia with others.
For Videos, Join Our YouTube Channel: Join Now
Read More:
- What is Machine Learning
- What is a Machine Learning Model
- Types of Machine Learning
- Supervised vs Unsupervised vs Reinforcement Machine Learning
- What is Deep Learning
- Feedforward Neural Networks (FNN)
- Convolutional Neural Network (CNN)
- Recurrent Neural Networks (RNN)
- Long short-term memory (LSTM)
- Generative Adversarial Networks (GANs)
No Comments